When it comes to software deployment, everyone has started with custom bash script doing the simplest job pushing built code onto the preconfigured server. But those times are gone and no one would ever get back to this, once they experienced the bliss of automated CI/CD setup.Making developers’ work easier is an integral part of the DevOps culture we believe in. Plus, there’s a company making a living from projects, where more finished tasks usually mean more earnings. And then there’s me, a DevOps Engineer focused on pure, fully independent code, who is able to deploy someone else’s code within minutes.All these things might be done with just one, properly configured CI/CD setup and here I’m about to briefly go through all the branches of our process, together with tools and solutions we decided to implement or adopt. This setup allows us to deploy the code without worrying about dependencies and the structure.
From raw code to final software deployment
Everything starts locally. Each developer, based on their Jira tasks, creates code representing the functionality clients expect. We do all that working in sprints.Working with Scrum does not only mean we split our work into sprints and we stay agile when it comes to our client’s needs. This agility translates straight into our DevOps team, where this approach pushed us to create the most flexible setup we’ve ever produced - a fully automated software deployment process.
But let’s start from the beginning.
Code
Apptension hosts our code on BitBucket. We do this from the very beginning and that won’t change in the nearest future. Hence we can take it as a constant part of the process. We divide real projects into BitBucket projects, where each of them has at least two repositories - one for the product code and one for the infrastructure code.Even though the first one does not require any explanation, the latter might sound a bit cryptic. We’re into Infrastructure as Code so much that we can’t even imagine our work routine without HashiCorp Terraform. That’s the tool we use for keeping our infrastructure, well… structured, where every change of the environment, no matter what cloud provider it is hosted on, is introduced with a simple code change and proper code review before it goes any further.Thanks to this, we can keep track of infrastructure changes during the project’s lifetime making it easier to maintain, update or recover any environment we need.When it comes to projects we take on at Apptension, there’s one thing we consider unchangeable - they’re based on Docker. There’s high pressure from our DevOps team on the development departments to use Docker for each coding activity ever taken. From simple Python scripts, to complex service-based project. We use docker-compose so it makes the development process even easier to live with. Everyone sees the benefits of such a standard. Then, based on docker-compose YAMLs, we define the production version of the deployment files and we keep them in a repository as well, so we track changes whenever they occur.
HashiCorp Vault
Every project requires an environment-specific configuration, so we introduced HashiCorp Vault into our stack years ago. That’s a quite simple yet powerful tool for storing secrets. We use it to customize environments during build or deployment. Strong policies control access to the secrets. Authentication takes place with tokens created for limited time, where permissions are limited strictly to what’s allowed within the established policies. The backend, which stores the data, is encrypted and real-time mirrored, so we feel very comfortable with the setup considering our secrets are safe enough.
Jenkins
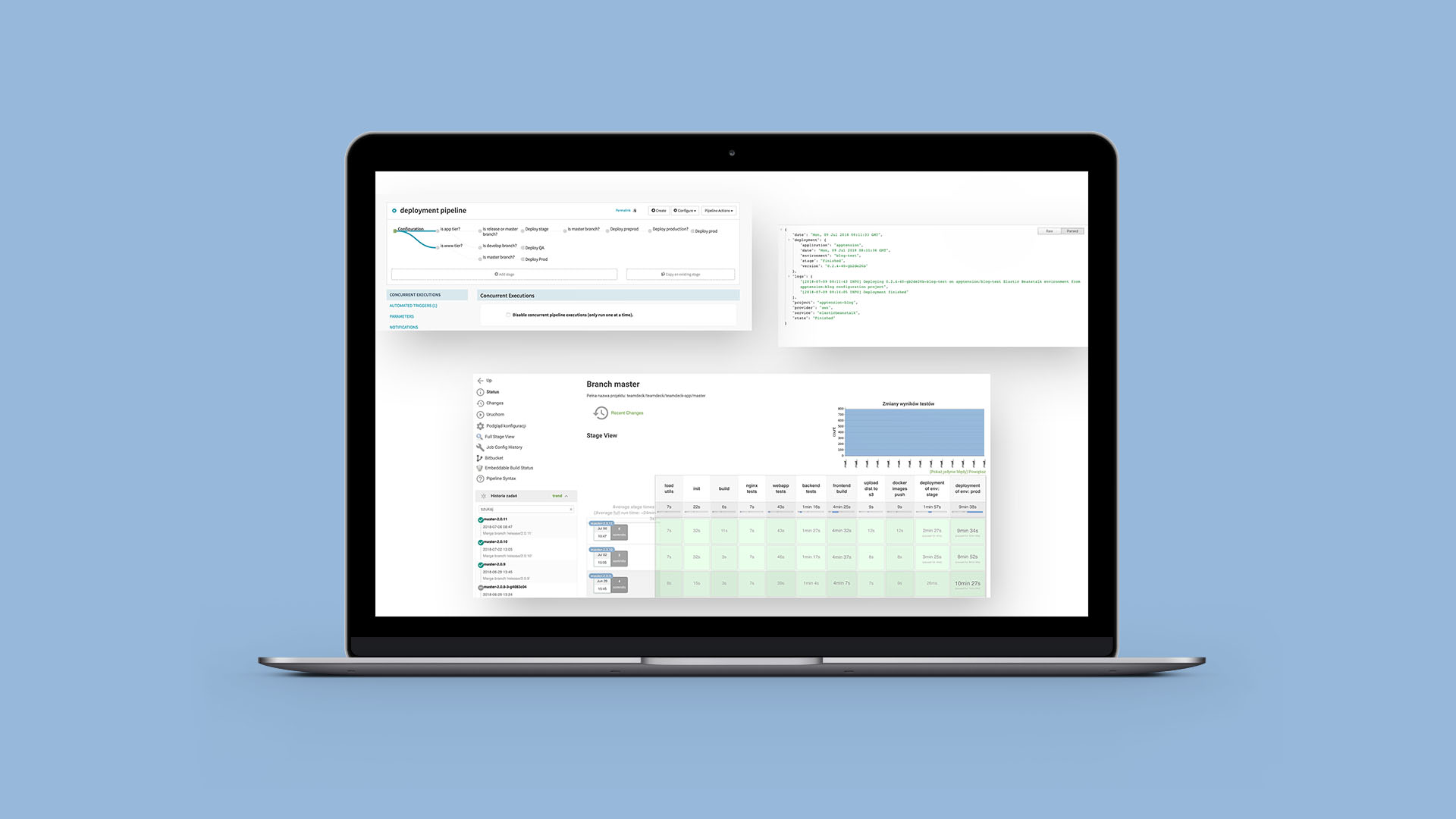
And that’s the clue. We can’t go any further without Jenkins. You may not like it, you may even hate it, but the undeniable fact is that it’s the most flexible CI we could have gotten back then. It’s been with us for 5 years now. We went through five code tsunamis, four deployment earthquakes and Jenkins still lives as it was years ago. We did some surgery, rewrote the code of the whole deployment logic more than four times and we still didn’t reach the final point, where we may rest with the feeling of good work done. There’s still some place to improve and Jenkins is ready for that.With Jenkins, we strongly rely on the Jenkins Pipelines. Our CI code is an inseparable part of the code it builds and we keep its history as it was the regular code. Working with Jenkinsfiles, written in Groovy, requires some adjustments to the overall view of the code and coding standards. There are some quirks specific for Jenkins only one needs to deal with. Jenkinsfiles are hard to run test against. Since they’re based on built-ins and plugins installed on a Jenkins instance, local testing is almost impossible. The key to success here is just pure experience gathered with each defeat in the uneven battle: developer vs. Jenkins. But when it’s done, it works like a charm.
Our Jenkins consists of a master job being deployed on Kubernetes cluster, which orchestrate jobs from the queue (invoked with webhooks from BitBucket on commit push or Pull Request update), and nodes of several types, where each has its specific dependencies installed. Currently, we use DigitalOcean droplets as raw instances and Kubernetes pods scheduled dynamically based on the queue size. Each job then locks one of the node’s workers using labels and starts its execution. Our code is cloud provider-agnostic. We support AWS and Google Cloud Platform, but at the same time we can use bare metals whenever we want to. We build Docker images, run tests of each kind and push the images to our cloud-managed Docker registries if everything went well. At the end of each build there is a simple decision tree which determines whether an extra environment needs to be build. If so, a webhook is invoked and a specific deployment service takes the initiative.
Deployment service
While Jenkins is the one man army when it comes to Continuous Integration, we rely on separate, external services for Continuous Delivery.Not so long ago we were deploying using Jenkins. Jenkinsfile contained the Groovy code and invoked Docker images with deployment code. Using simple parameters we were able to deploy anything without leaving Jenkins. But as time went by, a need for a separate, independent service arose. Maintaining deployment configuration based on Jenkinsfile required us to edit it separately for each project’s repository. We didn’t want to perform repetitive actions, hence the need of a new approach.Since we mainly focus our efforts on AWS and Google Cloud, we had to find tools suitable for each of them. We’re using Elastic Beanstalk from AWS and Google Kubernetes Engine from Google Cloud. So we’ve prepared our Infrastructure to be ready for those primarily.
Spinnaker for Kubernetes
I won’t be describing Kubernetes here. There are tons of good articles about it.The fact is, we love it. It opens new paths for container management leaving the need of writing custom solutions behind. We use it for projects where scalability, agility are crucial and so is rapid software deployment.When we started working with Kubernetes, we ourselves created the code responsible for deployment, validation and rollbacking the code on errors. It was based on kubectl and contenerized. It contained the logic as well as the decision tree of commands invoked with kubectl and provided credentials. It worked well, but required extensive maintenance at the same time.Then Spinnaker came into play. Being a fan of the way Netflix handles containers in their services, I had to give it a try. After all, Netflix cooperating with Google, can’t be wrong on how to deal with containers. Since then, Spinnaker has been handling the Kubernetes deployment for us with ease. We started with Kubernetes Provider V1, based on JSONs. It had its problems, some of them were still unfixed until V2 became public. Configuring services with JSONs with different keys comparing to standard Kubernetes YAMLs quickly became a nightmare. We’ve encountered several issues, especially when we tried to define environment variables being gathered from Kubernetes Secrets, where V1 could not handle the change properly. While V1 was acceptable, we deeply believed a YAML-based solution would take this tool to the next level.And it did!
The manifests-based V2 Kubernetes Provider solved most of the issues we’d encountered previously, letting us keep the code clean and being almost identical to YAMLs we would use with kubectl.Now, we can deploy anything packed into containers, scale it within seconds as a reaction to the increasing traffic and replace versions in production with just small steps.
Custom Python-based service for AWS Elastic Beanstalk
AWS Elastic Beanstalk was not that kind to us as Kubernetes was. While solutions for Kubernetes started growing almost exponentially, AWS EB, which we use for simpler projects, still doesn’t have its main deployment tool that would meet our needs, especially when it comes to automated rollback on errors. We had to create one.Firstly, we started with a simple Python and boto-based application packed into Docker image (we called it eb-deployer). It was then run within Jenkins job as a container, taking a few arguments and files on the way and resulted with deployment rolling on.But, as with everything, there was a need for version 2.0 of it. While 1.0 worked as expected, it was firstly created as MVP. It quickly turned out we’re losing control of how it spreads across our setup, hence the need for a mature version. A well-defined and tested one. First off, a new catchy name, so it will be easier for us to think of it as a ready service, was created. It turned out binstalker was the name to go. Simple yet fancy.Then, the whole idea became a deployable service invoked with simple POST request. As for now, it’s a centralized REST API we can deploy within minutes and it functions on a Kubernetes cluster. It takes requests, validates them and puts them on the Redis Queue. Then, scalable workers consume tasks, create deployments and invoke AWS API with the boto3 package.
Everything is held in one place and fixes are implemented almost immediately for every service that relies on it. Jenkins can keep the track of the results, as binstalker returns specific endpoints for states and logs querying. The code itself is capable of validation, deployment, logs querying, health checking and eventual rollbacking to the previous version when newly created deployment fails checks. Creating custom tools allow for functions perfectly matched to the process’ needs. And sometimes there’s even no other way than roll up your sleeves and do the coding as we did.
Results
I took you through our complete software deployment process describing briefly every tool that affects the final result: a successful deployment on a specific environment of a specific project.Currently it’s a well oiled machine that (with some help from DevOps team) does hundreds of builds for roughly 10 projects a day. We have to monitor its behavior, so it does not fail in the most inappropriate moment. We have to control nodes, so they aren’t stuck making the Jenkins job queue bigger. While it still requires some operational time of the DevOps team, we’re still minimizing the time we spent on “manual” work.Deployments, on the other hand, are fully automated and don’t require any support barring serious issues.All that results in a complex but rapid process for build and deployment, where the code starting its way with a simple git commit && git push, is then heavily tested and ends as specific version on the web environment usually within 10 to 15 minutes.Each time a developer pushes the code to their repository, the story begins again. And we, the DevOps team, are very proud of that.