
Dive into the latest chapter of our journey with Mobegí, the AI assistant reshaping company knowledge access. This part focuses on rigorous evaluations ensuring Mobegí's stellar performance. We detail our approach beyond traditional metrics, integrating tools like Langsmith for debugging and the LangChain Expression Language (LCEL) for efficiency. Learn about our innovative dataset creation, blending automated testing with human insights.
Join us to see how we're perfecting Mobegí for a transformative user experience.
Validating progress
LLamaIndex documentation makes a good point using the software testing analogy: much like how integration tests and unit tests are equally important, evaluating the end-to-end behavior of the application and its subsystems is crucial.
We found the flow in this particular domain is less rigid, probably because of its non-deterministic nature. You may check the end-to-end behavior first, detect some failures, and get deeper into the different subsystems to understand which ones are responsible. You may also focus on the retrieval subsystem, assuring the first n-retrieved documents are effectively relevant.
One thing that was very clear from the beginning was that we needed a scalable, automated way to test the app's performance during development. Not to replace human supervision but to integrate it and give solidity. Reliable automated testing provides a sound foundation across the development lifecycle while retaining indispensable human perspective.
How we evaluate LLMs
Traditionally, NLP models were evaluated on task-specific benchmarks suited for those constrained applications. However, as language models have rapidly advanced into expansive, multi-domain LLMs, the severe limitations of conventional metrics have become starkly apparent. These early methods simply cannot adequately measure emerging capabilities, now pushing far beyond narrow scopes.
Legacy benchmarks were designed to assess performance on solitary tasks, not to test adaptable ingenuity across a spectrum of skills. And while vital for progress then, pursuing incremental gains in dated evaluations risks hitting dead ends. We must fundamentally reimagine assessment to align with AI’s escalating generality.
As LLMs have matured, our collective strategies have co-evolved, leading us to recast the models themselves as indispensable guides to benchmark progress.
We recognize the self-evaluation approach has immense promise. That said, we believe a comprehensive assessment framework balances the innovative capabilities of LLMs with the proven accuracy of human judgment.
For us, responsible innovation demands evaluation as wise counsel, not arbitrary referee – illuminating complexity, not handing out penalties.
If you are interested, “Decoding LLM Performance: A Guide to Evaluating LLM Applications” by Amogh Agastya is an excellent source for learning more about the topic.
Langsmith adoption
Early stages
We adopted Langsmith early on, shortly after the LangChain team launched it, for test and debug purposes.
The choice felt natural – we could keep our tracing private and its integration was literally two steps away:
- creating an API key on Langsmith
- adding 4 environment variables to the project
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
export LANGCHAIN_API_KEY=""
export LANGCHAIN_PROJECT="my-first-langsmith-run"The interface allows you to monitor your entire application execution process, providing essential metrics such as token usage and latency and broken down into each single subprocess.
We went from manual console checking to a clean and well-organized UI, providing our team essential visibility into model performance through shareable, persistent run histories.
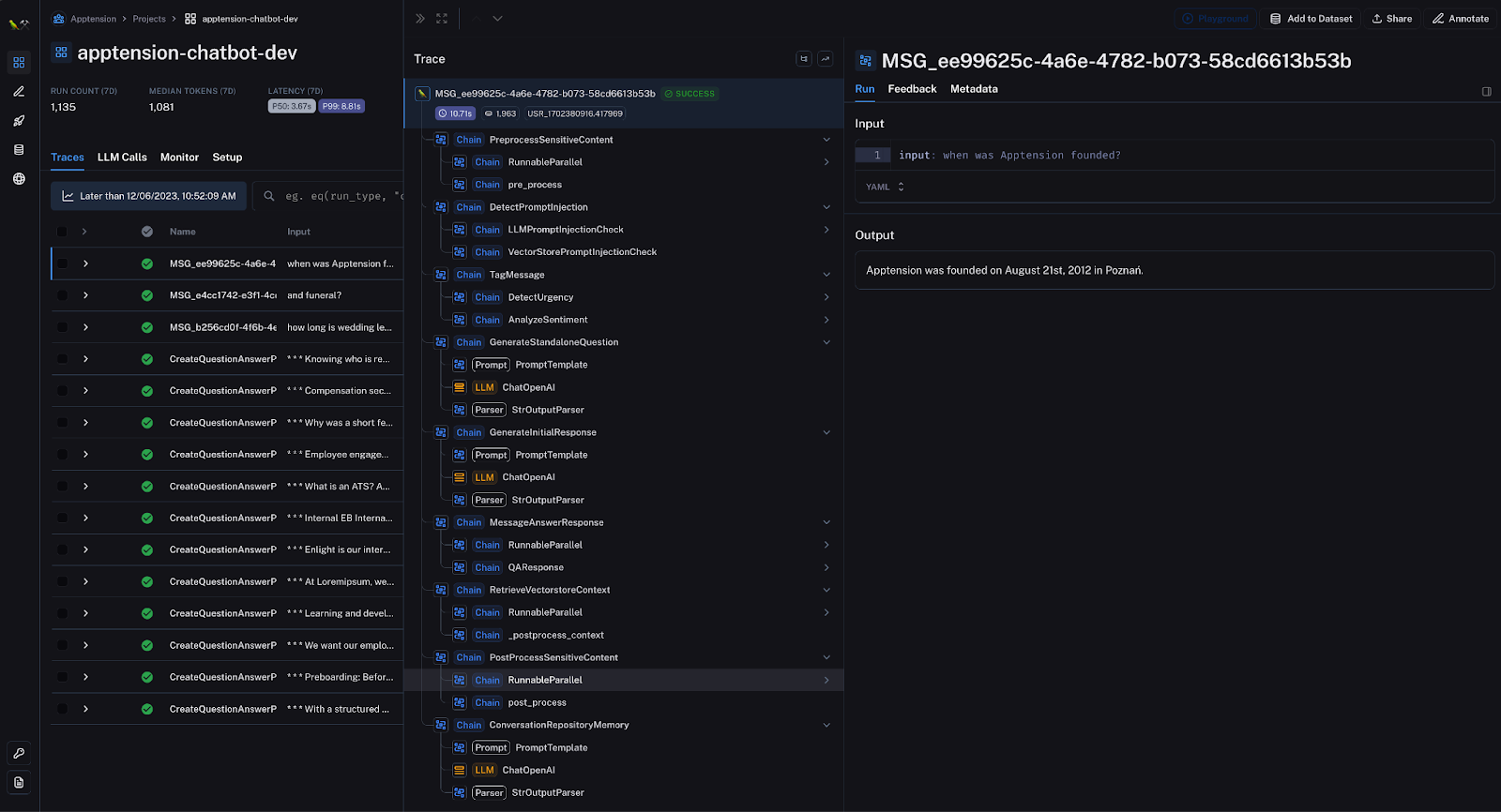
Run, Mobegí, run!
LangChain's subsequent release of the Expression language (LCEL) led us to refactor our codebase.
To grasp the concept, with LCEL you go from here:
chain = LLMChain(
prompt=prompt,
llm=model,
output_parser=output_parser
)
out = chain.run(prompt_param="Once upon a time")To there:
lcel_chain = prompt | model | output_parser
out = lcel_chain.invoke({"prompt_param": "Once upon a time"})It immediately stood out for its elegantly clear declarative syntax.
The full benefits of its adoption and its soft learning curve are beyond the scope of this article, but, if you want to know more, “Demystifying LangChain Expression Language” by Rajesh K is an interesting read about the topic.
What proved most significant for us, though, was that in order to introduce LCEL, the LangChain team had to unify all system components under the Runnable interface, greatly easing maintainability.
It meant we could finally assess subsystem combinations and overall results using consistent test data and processes.
We could validate changes through the same interface we used to construct them.

Dataset generation
Our initial in-house dataset covered limited samples from colleagues – typically called a “golden set,” given its hand-curated relevance. We welcomed its small size because it is also the most likely case in a real-world scenario.
To complement our golden data, we utilized an LLM (OpenAI GPT3.5) to create a synthetic "silver set" of question-answer pairs. Surely, it lacked guaranteed real-world alignment. However, papers like "Conversational QA Dataset Generation with Answer Revision" and the implementation of the process in frameworks like LangChain and LLamaIndex showed thoughtful synthesis can simulate useful testing signals to compensate for limited samples.
Even without an answer revision mechanism in our case, the silver set still proved valuable for steering solution development. It also served as a compass when improving evaluation results based on specific data points of the golden set.
Silver dataset generation pipeline
Our current dedicated pipeline offers flexible options for synthetic dataset creation. It can run automatically at data ingestion time, and it can also be triggered on demand.
Both options ultimately:
- generate the silver dataset using the entire pages corpus for a given world data version (more about data versioning here)
- upload the resulting question-answer pairs to Langsmith for expanded testing.
For each document, we instruct the LLM to generate contextually relevant questions using the following prompt:
Generate a list of up to 3 question-answer pairs regarding the Text.
Try to ask contextually important questions, and not generic ones.In our roadmap, we plan to enhance this synthesis process and create specialized datasets targeting particular capabilities like people-focused retrieval or prompt hacking defenses. These tailored synthetic datasets will complement the broad coverage corpus by enabling more rigorous testing of key subsystems and features beyond what our manual golden data can feasibly cover.
Feedback dataset
The user feedback we request at query time gets programmatically logged within our Langsmith instance for each exchange. Over time, aggregated grades and qualitative notes accumulate and are stored as part of the run history.
Conveniently, LangSmith allows developers to convert the inputs and outputs logged in any runs as a dataset. We hope that, once Mobegí is released to the rest of the company, we will collect enough quality labeled data to create a dataset from there and integrate it as part of our evaluation framework or to fine-tune an embedding model.
You can find more details about this in the next chapter.
QA pipeline evaluation
LLM-based evaluation methods are promising, but they aren't without issues. In a recent article on their blog, the LangChain team covers the challenges and current limitations of this approach while testing their set of evaluators on common tasks to provide guidelines and best practices.
When datasets contain labels or ground truths, LangChain presents 3 different evaluators, namely qa, context_qa, and cot_qa:
- qa evaluator (Correctness): Based on reference answers, decide if a response is correct or not.
- context_qa evaluator (Contextual accuracy): Based on the context of example outputs (without ground truths), decide if a response is correct or not.
- cot_qa evaluator (COT contextual accuracy): Using the chain of thought reasoning (instead of context), decide if a response is correct or not.
They determine how the response is evaluated in terms of its accuracy and correctness.
LangChain also offers criteria evaluators. Most of them don't need a reference – they are used to determine what to look for in an evaluation. A set of pre-built ones covers aspects like the helpfulness of the information retrieved, the relevance and coherence of the responses, and their potential controversiality or maliciousness.
On top of those, it is also possible to create custom criteria evaluators.
At the moment of writing, the model that best performs as a judge is OpenAI GPT4.
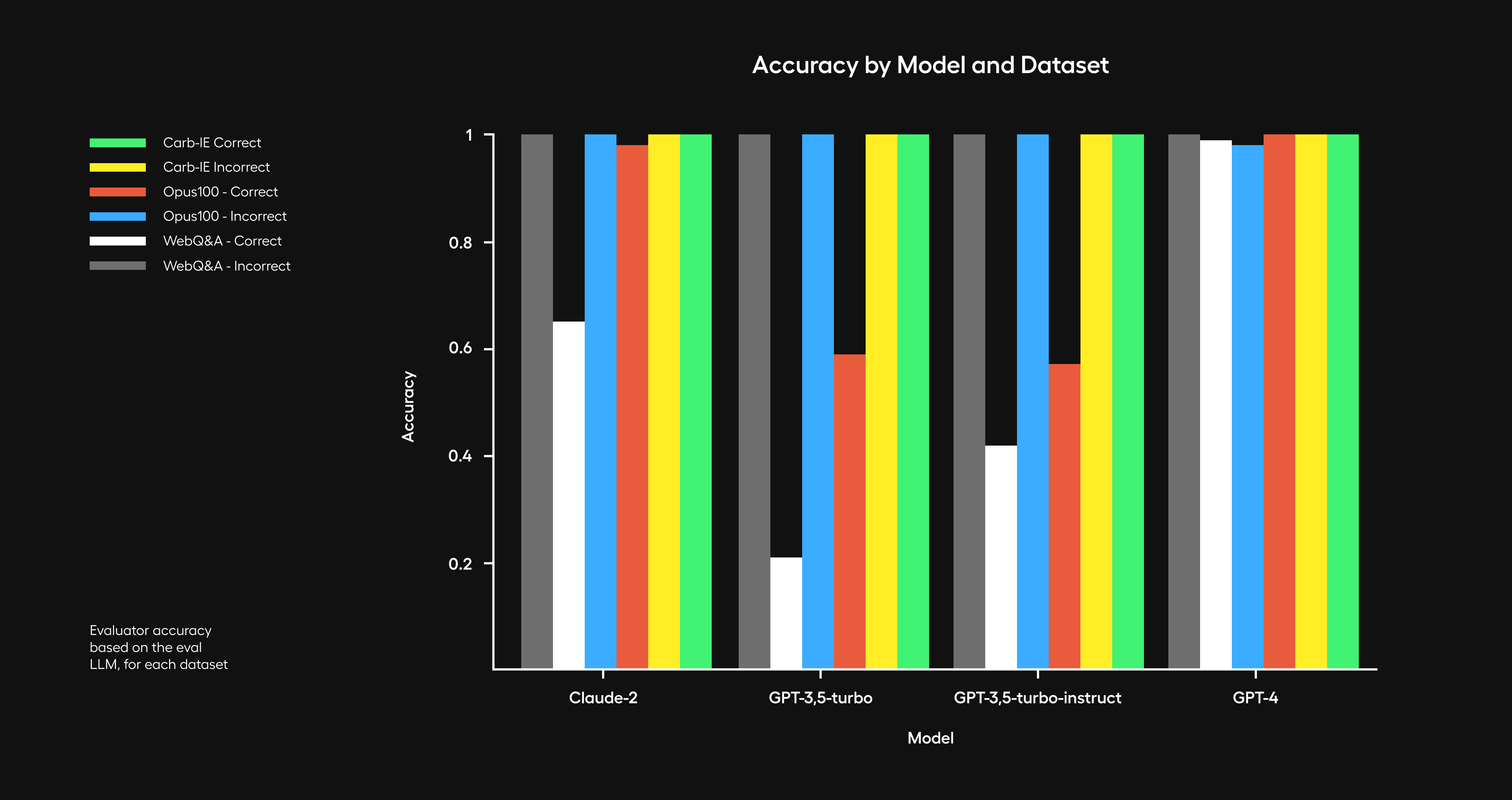
Both types of evaluators are equally important to assess practical applications; a detailed overview and insights into various evaluation techniques can be found in LangChain documentation.
We configured our evaluation pipeline using the following:
- A cot_qa evaluator
- The following criteria evaluators:
- Conciseness – determines if responses provide the necessary information without excessive wordiness, which could lose user focus. Values brevity.
- Relevance – checks that pipeline answers directly pertain to the question's intent and details. Misalignments indicate flaws.
- Coherence – assesses logical flow and clarity of responses. Incoherent passages suggest instability.
- Helpfulness – estimates the utility delivered by the answer as supplementary decision support for the next steps.
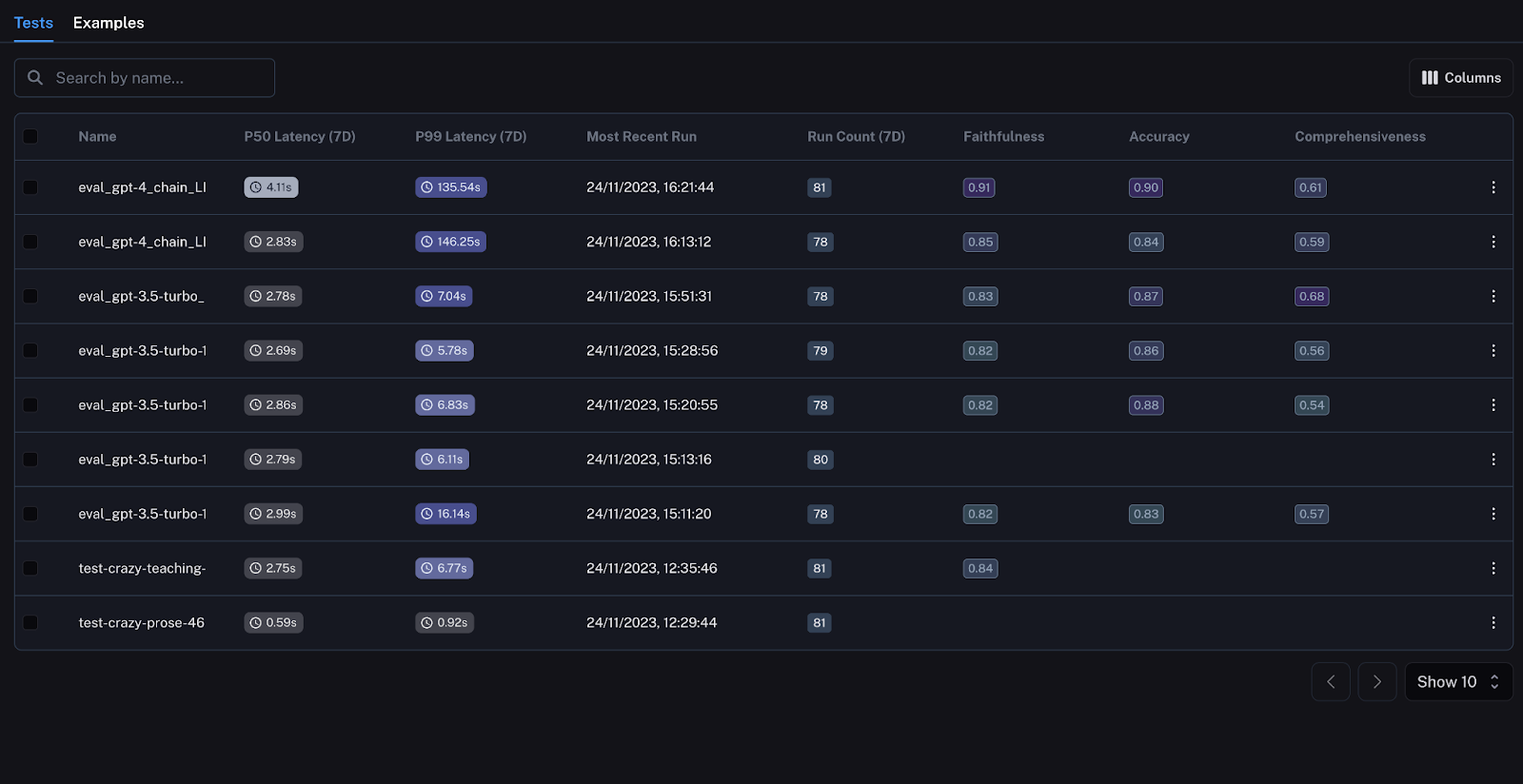
A key advantage of using Langsmith is the ability to pivot from high-level metrics to granular instance dives seamlessly. Once test runs are complete, the rich runtime logs retain full request-response traces at each pipeline stage.
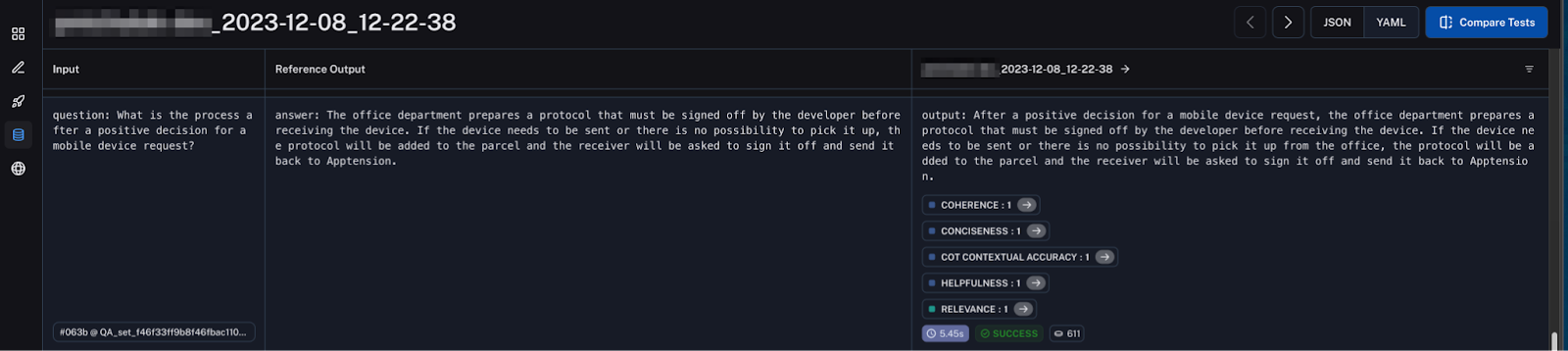
By selecting a particular problematic data point, we can jump directly into the integrated debugger on that exact exchange and visualize the input payload as it transforms through each component.
Coming next
Thank you for following along as we covered key aspects of our evaluation strategy. We saw how data synthesis may help even with its current limitations and how Langsmith enables robust, reproducible testing.
Next, we'll conclude by unveiling our roadmap – a sneak peek into the future as we outline plans toward the shifting horizon of Generative AI.