
Welcome to the last stop of our journey into the world of generative AI, in which you could get to know Mobegi, our AI assistant. This part explores the roadmap with steady, incremental improvements, such as enhancing people-focused retrieval, enabling multi-source document ingestion, allowing verified answers caching, facilitating self-learning, and implementing the comparison pipeline – showcasing our commitment to innovation and adaptability.
Read on to understand the technologies behind Mobegi even more.
Second star to the right
We aim to release the tool to the rest of the company in a few weeks. Real users, real adoption patterns – finally, a chance to gather more feedback beyond our assumptions. Both numerical data and subjective takes will prove invaluable. Does it help efficiently? Do teams actually use it? We'll soon find out what resonances and gaps emerge in the wild.
While much refinement lies ahead, recent innovations like Self-RAG and multimodal RAG show promise for dramatically advancing relevance and reasoning over time. For more details on the state-of-the-art “Innovations In Retrieval Augmented Generation” by Skanda Vivek provides a great research overview.
Our current roadmap, however, focuses on more incremental enhancements before pursuing such advanced capabilities.
People focused retrieval
While the initial retrieval implementation has generally proven effective, we've identified a performance decline when queries involve individuals or specific roles/departments.
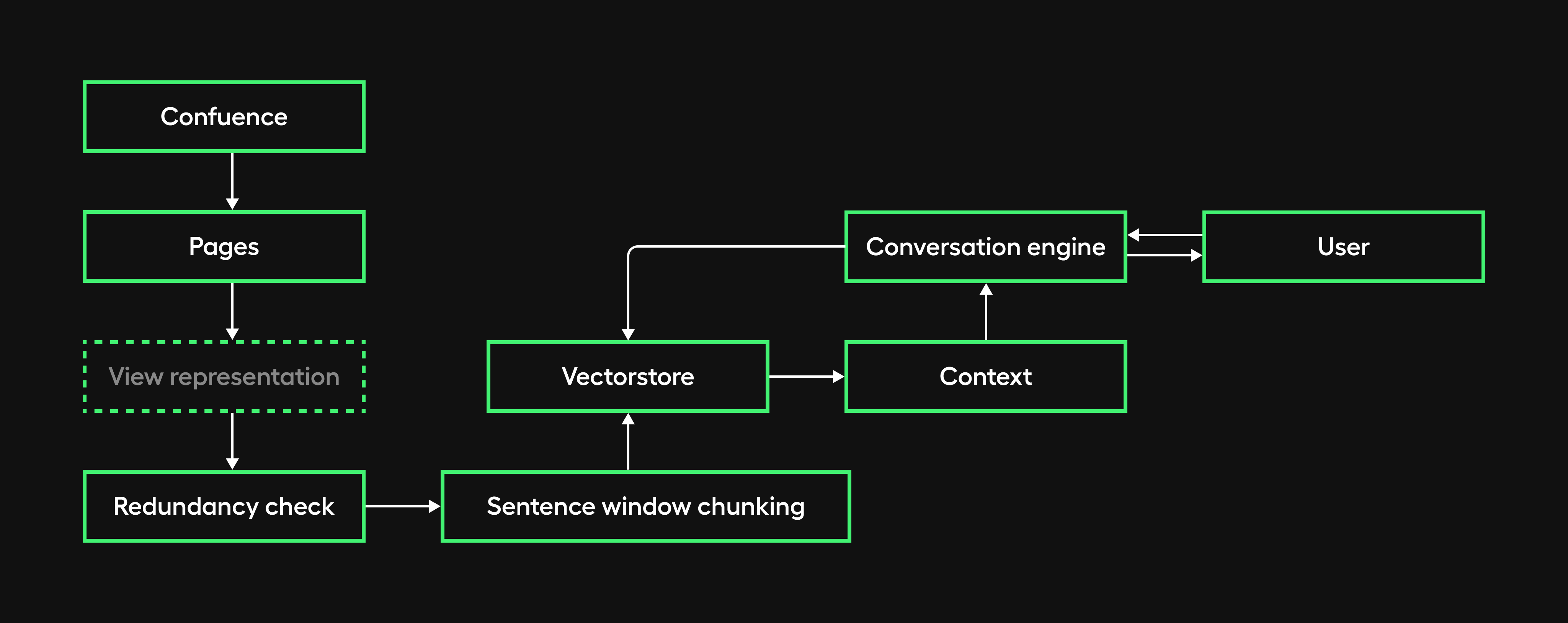
To address this limitation, we are transitioning to a dedicated retrieval agent equipped to handle people-oriented searches better.
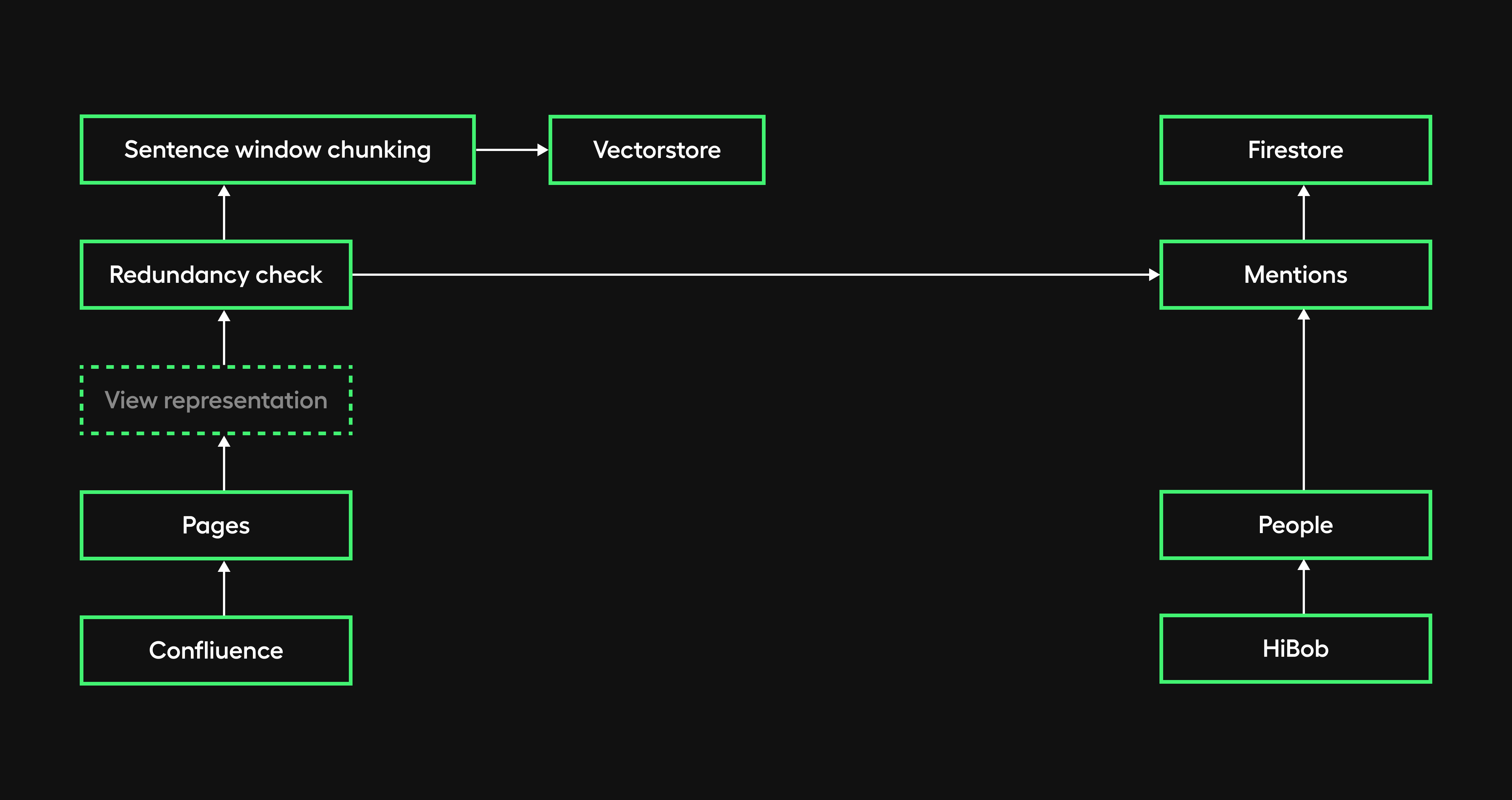
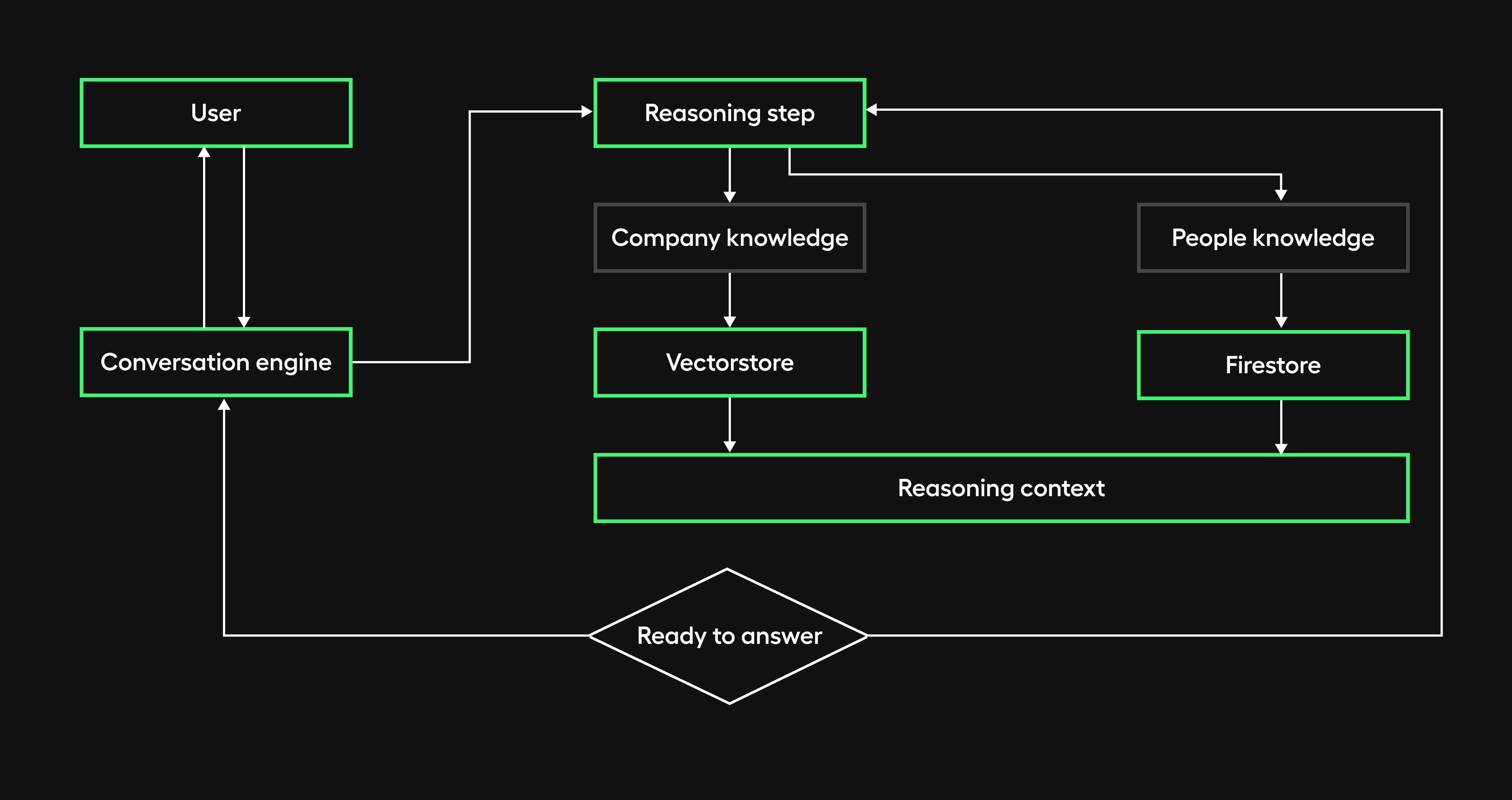
During data ingestion, we plan to implement a separate knowledge people collection in Firestore containing anonymized details such as names, roles, and document mentions for each person.
The retrieval agent will leverage this collection to conduct targeted searches when a query is recognized as people-related. The relevant results will then be used to enhance the information provided in the response.
Additionally, we will integrate the HiBob HR used by our company as the record system for people's data going forward. Consuming reliable, up-to-date employee information from HiBob's API represents a sustainable long-term solution.
Comparison pipeline
We have already generated the first dataset to evaluate the whole conversation engine’s accuracy. We plan to:
- Create several other ones to test retrieval relevance and security at least,
- Evaluate the Embedding model fine-tuning we described in the chapter about our conversational system. For this step, we want to collect around 100 feedback data points first.
We also plan to investigate more advanced techniques like paraphrasing, which uses models trained explicitly to rephrase text in meaning-preserving ways. This creates alternate forms, exposing logic gaps.
Fortunately, with Langsmith, comparing is just a click away from running evaluation tests.
We are also interested in investigating a slightly more sophisticated implementation.
Picture a scenario with a main and a development branch, each with its unique configuration. When submitting a pull request to merge the development branch into the main one, we could run the comparison as a GitHub action. Assuming we set rules and criteria to define “better,” we could allow the operation only if development performs better than the main.
Multi-source document ingestion
As one outcome of collaborating with the office team, it came to light that certain documentation pages contain links to Polish PDF files, offering updated content on specific topics.
We immediately saw this challenge as an opportunity to address aspects of data ingestion that we hadn't previously covered:
- Multi-format data: very likely in real-world scenarios where data comes in various formats.
- Multi-language data: given that most of our documentation is in English, we opted for a translation approach. We want to enhance it using back-translation – a technique leveraging dual-direction model architectures to translate text into other languages and back to the original language. This process helps uncover and resolve ambiguities.
- Consistency check: as a part of our workflow, whenever a document is added or updated, we thoroughly check for contradictions with existing knowledge. If discrepancies arise, we strive to identify the reliable source and handle cases where determination proves challenging.
Hypothetical questions
This approach was first introduced in the paper “Precise Zero-Shot Dense Retrieval without Relevance Labels” by Luyu Gao, Xueguang Ma, Jimmy Lin, Jamie Callan.
It involves both ingestion and retrieval phases.
- At ingestion time, we ask an LLM to generate a question for each chunk and embed these questions in vectors, adding the chunk as metadata.
- To address potential biases in the autogenerated questions, we will institute auto-evaluation mechanisms that assess relevance and utility. This will help mitigate the risk of low-value questions that poorly inform the search.
- At runtime, we perform the query search against this index of question vectors and then, after retrieval, route to original text chunks and send them as the context for the LLM to get an answer.
This approach potentially improves search quality due to a higher semantic similarity between a query and a hypothetical question compared to what we have.
A deep dive read about the topic is “Power of Hypothetical Document Embeddings: An In-Depth Exploration of HyDE” by azhar.

Verified answers caching
We’d like to delve into the potential of 'caching' verified accurate responses to enhance efficiency and minimize both cost and latency. In our initial exploration, we aim to implement a vector store to assess semantic similarity and employ paraphrasing techniques.
We also want to investigate existing solutions, such as GPTCache.
Self-learning investigation
Before we have enough user feedback to guide fine-tuning, we wanted to investigate strategies the app could use to learn from preferences once we collect them.
In particular, Contextual Bandits and Reinforcement Learning may help to re-rank retrieved documents over time for better relevancy. Contextual bandits are algorithms that serve back the currently best-known options more often based on incoming data while still occasionally testing alternatives. Reinforcement learning systems explicitly explore different rankings, measuring the impact of those variants to reinforce the ordering that maximizes a reward signal - in our case, user feedback.
Routing
Once people-focused retrieval matures, we could integrate routing to recommend the best human contact if the conversations struggle.
For example, after multiple turns unable to satisfy an inquiry or for broad requests better handled interpersonally, our application could seamlessly escalate to the ideal subject matter expert equipped to resolve it.
At the same time, we could provide them with more context using the conversation memory.
This creates a supportive handoff funnel complementing automation - preserving context while acknowledging system boundaries through trusted peer guidance when suitable.
A note about Brain module configuration
While configuring the Brain module, we noticed an analogy between pipeline steps and agent tools - both encapsulate logic with defined inputs and outputs. This overlap means steps and tools could plausibly converge into a single configurable entity.
What remains to be explored is how we can describe
- input-output connections when they are used as steps in a pipeline,
- conditional step execution.
However, it is very likely we’ll eventually refactor to consolidate steps and tools into a unified entity, an “instrument” in our orchestration that can be configured once and play as both.
Of course, appropriate descriptors like data shapes and schemas to enable connecting instruments’ outputs to compatible downstream inputs will be crucial. Runtime type checking and transformations can rely on this.
Additionally, pipeline sequence metadata on the order of operations, conditional logic, loops, etc. will allow orchestrating instruments appropriately. Versioning details on creation dates, deprecation timelines, change logs, etc., can drive update scheduling and manage impacts as instruments evolve.
Looking ahead
Thank you so much for joining us while covering Mobegí's journey so far – from early architecture calls to capability growth to where we go next. We really appreciate you sticking through the series!
It’s both thrilling and challenging to keep pace with the rapid innovations that continuously expand the possibilities within generative AI. Like a nebula, the field evolves daily, revealing new frontiers. We are still convinced we spot coffee there and as good devs, it will still fuel our hands-on explorations.
The road ahead promises to be exciting. We welcome you to continue this journey with us through our forthcoming articles as we discover what’s next together.